Guide
Basic How-To
- Browse the collections by date, or use the search features on the sidebar to seek out when particular people or words were mentioned. We recommend you start with a basic search, under "Search the archives", for the sake of simplicity. Filtering and sorting options will become available after a search is conducted.
- To limit searches to an exact phrase, you can use quotation marks, e.g.: "Emmerson Place", "Grand Trunk Pacific", or "tax sale supplement", although results with all three words will take priority even without quotation marks.
- Results are sorted by the computer's guess at the relevance of the result to your query, the most relevant first. If you want to sort your results by date, you may use the "Order Results by Date" link. This will display the results in reverse chronological order (most recent to oldest). To display the results in forward chronological order (oldest to most recent), simply click the link again.
- Seeking back and forth inside an issue will generate a lot of URL history in your browser, necessitating many "Back" presses to get back to your search results. This can be addressed in two ways: 1) Open issues from the results page in a new tab (right-click on the link or the image thumbnail, and select "Open Link in New Tab") or 2) Perform a long left-click on your browser's back button to see a brief history of previous pages viewed in the current tab, and select the Search Results (they should appear several items back).
- To sort your search results by date, click the "Order results by date" link. To reverse the order, click it again. This affects only the current search results - if such ordering is required for a subsequent search, you will want to click the link again to sort those results after they have been first presented to you.
Sharing
There are numerous ways to share the content you find here - for example, there is a sharing button inside the issue viewer (top right), so you can link others to what you are viewing. (The URLs can be quite long, so you may want to hide them behind a hyperlink by highlighting specific text for the link and then inserting the link - exact procedure will vary depending on your e-mail client (e.g., Thunderbird).) You are also welcome to download and e-mail PDFs, although in some cases they will be too large for some e-mail servers. Alternatively, you can share the link to download the PDF - simply right-click on the link, "Copy link location", and paste it in an e-mail. You can also get the link to the entire issue by right-clicking (or long-pressing, if on a touch screen) on the View tab and copying the link, which can then be pasted where needed, or link to individual pages by clicking on the Pages tab and then, when the list of pages is displayed, copying the appropriate page link.
If you are interested in clipping out an individual article, there are at least two methods: 1) Download the PDF and open it in Adobe Reader. You can then use their selection tool to highlight an area and then copy it to the clipboard (for pasting into an e-mail or an image editor). 2) Take a screenshot from the browser view of the article using a clipping tool such as Greenshot (for Windows; Windows also offers built-in snip tools for Windows 7 - 10 and a new tool with annotation capability for Windows 10 (on up-to-date Windows 10 systems, you might try the key combination Windows + Shift + S to start it, then the left option to take a Rectangular Snip)). On Linux-based operating systems, Shutter may be a good fit for the same purpose. These sorts of tools can be configured to save a clipping to your system and to place a copy on your clipboard simultaneously. Exact procedures will vary depending on the specific tools used. In general, you will want to be zoomed in to a readable distance as you will be copying no more and no less than what you are currently viewing.
For incorporation in non-commercial deriviative works, we recommend downloading the original TIFFs of the pages you need, so as to be working with the highest-quality images possible.
Advanced Search
This can be used to combine keywords or limit your results to specific newspapers (at a future date). Use the "+" button to add additional fields or instances of the same field. "OR" will generally be more useful than "NOT" - if used with Text, the latter stands the danger of eliminating results that would be relevant to you, as the smallest scope of search is an entire newspaper page, not a single article in a page. (Technology to automatically split scans of newspaper pages into individual articles was not available in the early months of 2019 when this archive was built.)
Unlike ordinary searches, keywords for advanced search do not automatically carry over from the search results into the issue views for highlighting purposes. However, you can still use the "Search inside" box at the top of the issue viewer to highlight and seek any specific words you might care to.
Field types currently supported for Advanced Search:
- Text: This field contains the text from a newspaper page as recognized by the computer. 95% of the time, this is the field you want.
- Newspaper Name: This field contains the name of the newspaper (for example, "Prince Rupert Daily News").
- Date: This field contains the release date of a newspaper issue, in the format YYYY-MM-DD. You can enter a year ("1932"), a year and a month ("1932-09"), or a complete date ("1932-09-06"). Any date filtering subsequently performed on the search results will be a subset of the overall results that are determined by this field. Best matches to a complete date should appear first, although you will also see other close matches (the matching is performed as if it is text). More sophisticated date filtering is available after any search, but this will help the most relevant dates appear near the top of your results. Alternatively, if you know the exact date you're looking for of a particular newspaper, you can always check the menu of dates for that paper (e.g., Prince Rupert Daily News) and use the issue viewer's search box to search for words.
If you would like us to attempt to add additional fields, please contact the Prince Rupert Library.
Troubleshooting
- Occasionally a page of an issue may fail to load into the reader. If this happens, use Refresh or Reload on your browser. The F5 key will accomplish this in many circumstances.
- Zooming in may be limited to three levels, and zooming in a fourth time may present a blank yellow page that will never load. If you wish to attain the highest-possible resolution, download the original TIFF file using the "Pages" tab on the initial view of an issue.
- You may experience occasional URL redirections, which will mean having to press Back twice to return to the previous navigated page. If you need to switch among multiple issues, you may wish to try using browser tabs. To load an issue or page in a new tab, right-click on the link or search result and select "Open Link in New Tab" (the exact wording will vary by browser).
- A few of the page-level PDFs have .bin filenames instead of .pdf. There is no functional difference - simply save the .bin as a .pdf and it should open in any PDF viewer.
- The computer's guess (using the Tesseract engine for OCR) at the text is not layered onto the downloadable PDFs. While such layering is not a feature in Islandora, it is technically possible to do outside of it (for example, using a tool such as OCRmyPDF), but the OCR that can be derived from these scans of microfilmed newspapers is error-prone as you can see from the search result text snippets. Furthermore, the layout of pre-digital newspapers is also difficult to code for, making selecting discrete regions of text very difficult. If you would like to copy a page of text as recognized by the computer, you may do so in one of two ways: 1) Clicking the "TEXT" button on the viewer (text is based on the page currently being viewed) or 2) going to the Pages tab of an issue, then selecting the page you want, then selecting "View: Text".
- In some cases we are using the OCR supplied to us with the images for the purposes of indexing. It is important to note that the OCR for the purposes of text highlighting is a separate process, performed by this server when new material is ingested. Therefore, there may be occasions where the indexed OCR differs from the OCR for highlighting. In general, the supplied OCR is of a slightly higher quality, so as the ingestion process moved along we have switched to including it instead of using the server-generated OCR for both indexing and highlighting. You may also occaisonally see a message saying "No Results Found" after following a search result through to an issue, if it so happens that the highlighting OCR doesn't have the term spelled the same way as the index. If this happens, try using the in-viewer search to search for part of the word.
- In cases where the OCR's interpretation consistently diverges, it may be helpful to search for multiple transformations of the term - e.g., mazzei mazzel
- Many very common words are not indexed: "in", for example.
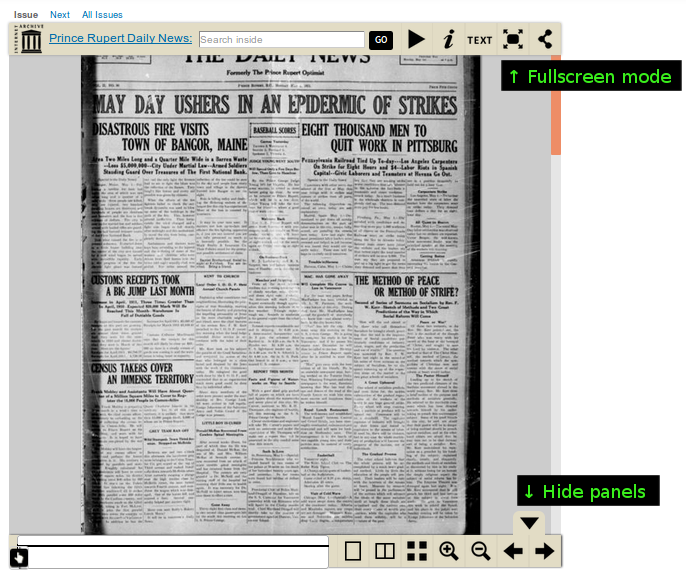
- The issue viewer control panels may cover a part of the top of the first page or the bottom of the last page that you wish to view. (For some longer issues, it may also cover the scroll bar handle - in such cases, click or press elsewhere on the scroll bar to uncover the handle, or place the mouse pointer over the issue and use the scroll wheel, or simply hide the panels using the button shown in the screenshot below.) To address content visibility in these circumstances, you can either go into fullscreen mode, or hide the panels: